AWS Glueを使ってS3にあるデータをAthenaで検索してみた

Glueを使う理由
Athenaで検索する場合、データベースを作成する必要があるがAthenaだけで行うと手動で設定する必要があり手間。Glueを使うと自動でカラム情報取得しデータベースを作成してくれるため便利。
やること
GlueでS3のデータカタログを作成し、Athenaで検索する
前提
S3はCloudTrailの証跡を使用する。
※ログ系のデータが格納されているS3バケットであればなんでも可
適当なバケットがない場合、下記を参考にCloudTrailの証跡を作成する
amegaeru.hatenablog.jp
実践!
1.Glue Crawler作成
1-1.[AWS] - [Glue]

1-2.[Data Catalog] - [Crawlers]

1-3.[Create crawler]

1-4.下記を入力
Name:crawler名
Description:任意

1-5.[Next]
![]()
1-6.下記を選択
Is your data already mapped to Glue tables?:Not yet

1-7.[Add data source]

1-8.下記を入力
Data source:S3
Network connection - optional:空白
Location of s3 data:in this account
S3 path:s3://aws-cloudtrail-logs-xxxxxx
Subsequent crawler runs:Crawl all sub-folders

1-9.[Add an S3 data source]
![]()
1-10.[Create new IAM role]

1-11.適当な作成するIAMRole名を入力

1-12.[Create]
![]()
1-13.[Next]
![]()
1-14.[Add database]

1-15.下記を入力
Name:database名
Description - optional:任意
Location - optional:任意

1-16.[Create database]
![]()
1-17.[Next]
![]()
1-18.[Create crawler]

2.GlueでGrawlerを実行
2-1.作成したCrawlerを選択し、[Run crawler]

2-2.下記を入力
Name:Crawler名
Description - optional:任意

2-3.[Next]
![]()
2-4.Crawler runsの[Last run]が[Succeeded]になることを確認

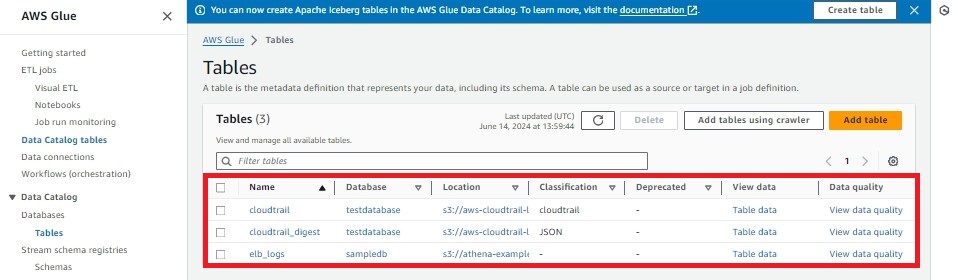
2-5.[Databases] - [Tables]

2-6.S3内のフォルダ情報が表示されていること
3.Athenaクエリ保存用S3バケット作成
3-1.[AWS] - [S3]

3-2.[バケットを作成]

3-3.下記を入力
バケット名:任意

3-4.[バケットを作成]
![]()
4.Athena設定
4-1.[AWS] - [Athena] - [クエリエディタ]

4-2.[設定] - [管理]

4-3.下記を入力
Location of query result - optional:項番3で作成したS3バケット

4-4.[保存]
![]()
5.Athena検索
5-1.[AWS] - [Athena] - [クエリエディタ]

5-2.下記を選択
データソース:AwsDataCatalog
データベース:作成したデータベース

5-3.テーブル名の[…] - [テーブルをプレビュー]

5-4.[結果]にクエリ結果が表示されることを確認

感想
たかだかS3の検索だけなのに結構手間だなと感じた。。。